
How to Choose the Right Primary Key

|
The Datanamic Team |
Choosing a primary key is one of the most critical decisions you'll make when designing a database. A well-chosen primary key ensures that every record in your table is unique, while also maintaining the integrity and performance of your database. But how do you decide between a natural key and a surrogate key? Let's break it down.
What is a Primary Key?
A primary key is a unique identifier for each record in a table. For instance, in a customer database, a CustomerID could serve as the primary key, ensuring that no two customers are ever confused.
Key characteristics of a primary key:
- Unique: No duplicates allowed.
- Non-null: Every record must have a value.
- Candidate for identification: It's often referred to as a 'candidate key' because it's a potential choice for uniquely identifying data.
Primary Key Types
When designing your table, you'll typically choose between two types of primary keys:
Natural Key
A natural key uses existing data, like login names, email addresses, or invoice numbers, to uniquely identify records. Examples include vehicle registration numbers or internationally recognized codes like country codes.
Surrogate Key
A surrogate key, on the other hand, is system-generated. Databases often use mechanisms like AUTO_INCREMENT, sequences, or GUIDs to assign these keys automatically. Surrogate keys are artificial and have no inherent meaning to the data they represent.
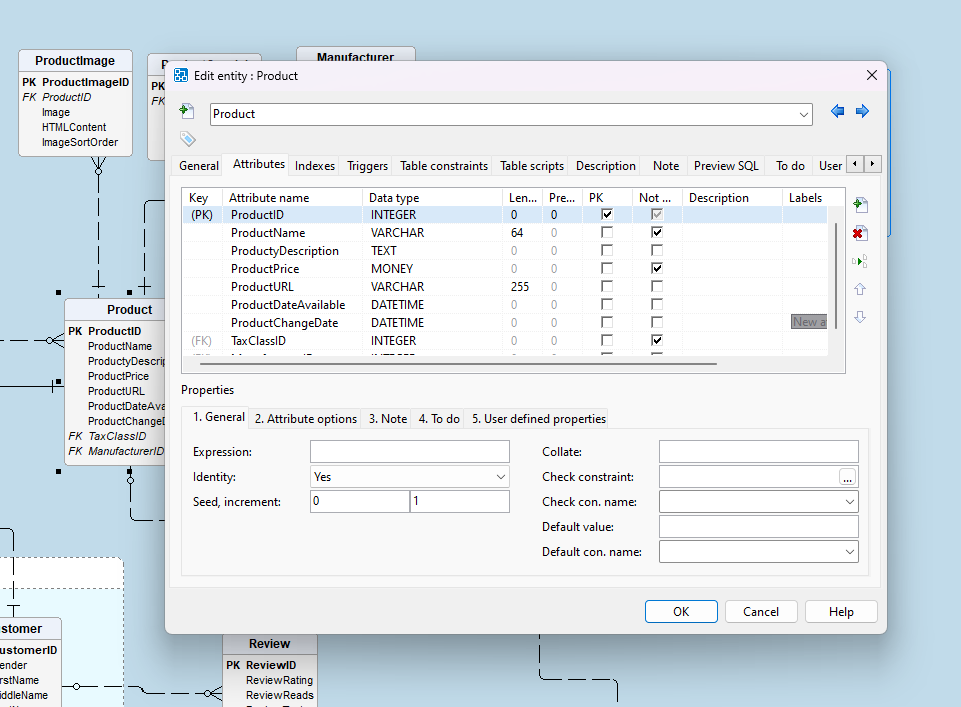
Surrogate key for the products table in DeZign for Databases.
The Debate: Natural vs. Surrogate Keys
In the world of data modeling, few topics spark as much debate as the choice between natural and surrogate keys. Each camp has passionate advocates, and the decision often comes down to your database's specific needs and context. Let's explore the key arguments on both sides of the debate.
The Case for Natural Keys
Supporters of natural keys argue that they are inherently meaningful and closely tied to the data itself. Natural keys, they say, align the database with real-world business processes. For instance, using an email address as a key in a Users table not only ensures uniqueness but also allows developers and users to intuitively reference records.
The natural key camp often emphasizes simplicity:
- No extra columns or indexes.
- Data integrity is closely tied to real-world constraints (e.g., a vehicle registration number is unique by definition).
However, critics highlight the potential pitfalls, such as the complexity of managing multi-column keys or the performance costs of larger key sizes.
The Case for Surrogate Keys
On the other hand, proponents of surrogate keys focus on their practicality and scalability. Surrogate keys simplify database design by providing a guaranteed unique identifier that is consistent across tables and independent of business logic.
This approach is particularly valuable in scenarios where:
- Natural keys may change due to evolving business rules.
- Candidate keys are complex, requiring multiple columns to ensure uniqueness.
- Performance is critical, as smaller keys are faster to index and query.
Critics of surrogate keys, however, argue that their lack of business meaning can lead to inefficiencies in real-world usage. For instance, when querying a database for a specific user, you often need to search by a natural attribute (e.g., email address) rather than the surrogate key, requiring additional indexes or joins.
Natural Keys: Pros and Cons
Advantages:
- Meaningful data: Natural keys have real-world significance, making them intuitive for searching and referencing.
- Efficient use of space: No additional columns or indexes are needed since the data already exists.
Disadvantages:
- Performance overhead: Larger or multi-column keys require more I/O operations, which can slow down queries and updates.
- Complex maintenance: Multi-column keys are harder to work with in development and maintenance.
- Ambiguity: With multiple candidate keys, it can be tough to choose the best one.
- Data dependency: You can't insert a record until the key value is available.
Surrogate Keys: Pros and Cons
Advantages:
- Stability: Surrogate keys are unaffected by changes in business logic.
- Simplified design: Consistent key strategies across tables make application development more straightforward.
- Better performance: Smaller, single-column keys are faster to query and index.
- Guaranteed uniqueness: No need to worry about duplicates.
Disadvantages:
- Extra overhead: Additional columns and indexes consume more disk space and increase I/O operations.
- Lack of meaning: Surrogate keys don't provide any business value or aid in search queries.
- 3NF violation: The key has no relationship to the actual data, which can conflict with strict normalization rules.
- Platform dependence: Implementations of surrogate keys vary across database systems (e.g., SQL Server vs. MySQL vs. PostgreSQL).
Making the Right Choice
As you can see, both natural and surrogate keys have their pros and cons. The best choice depends on your specific use case and environment.
To decide:
- List the trade-offs: Identify which disadvantages are deal-breakers for your application.
- Analyze your data: Consider the structure and usage patterns of your data.
- Think long-term: Choose a key strategy that supports your application's growth and scalability.
Remember, there's no universal answer. The 'right' key is the one that best fits your needs.
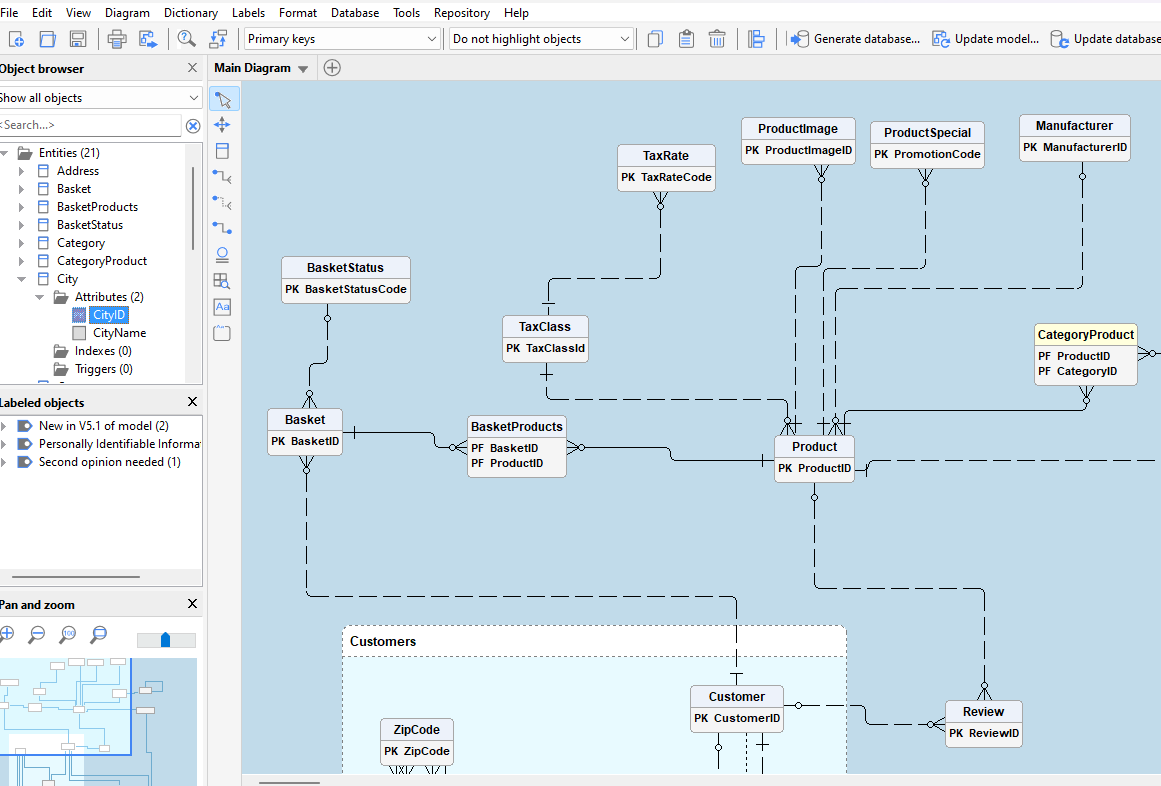
DeZign for Databases displays the primary key attributes for each entity in the entity box when setting display level to Primary keys.